Overview and basic usage
Evals are static, ground truth datasets designed to be run multiple times against your agents to assess their performance. These datasets are comprised of multiple test cases which are pairs of inputs (query or plan) and outputs (plan or plan run).
Running an Eval simply means putting the input of the test case through your agents, and comparing the output it yields with the test case output to make sure it's still behaving reliably. Any number of changes in the agents can cause a divergence from the expected output e.g. changes to your underlying system prompts, tool definitions, LLM choice etc.
Please make sure you have a PORTIA_API_KEY set up in your environment to use Steel Thread, as it relies on plans and plan runs stored in Portia cloud.
Basic usage
The overall flow is:
- From the Portia dashboard, create a new eval dataset including at least one test case. You can add existing plans / plan runs directly from the dashboard to use as test cases so you don't need to create them from scratch. Note that the query and tools will be automatically populated as test case inputs, but you can still edit those.
- You can rely on the default evaluators offered by Portia or create your own. Feel free to explore the available defautl evaluators in the dashboard. We will explain those in more detail below.
- Run your Evals by passing the name of the Eval dataset to your Steel Thread instance along with your preferred evaluators.
- Visualize the metrics from each run in the Portia UI.
Here is a step-by-step walkthrough with screenshots from the Portia UI.
- Eval Test cases are designed to be generated from existing data making it easy to do. You can also create a new test case from blank though if you'd like to!
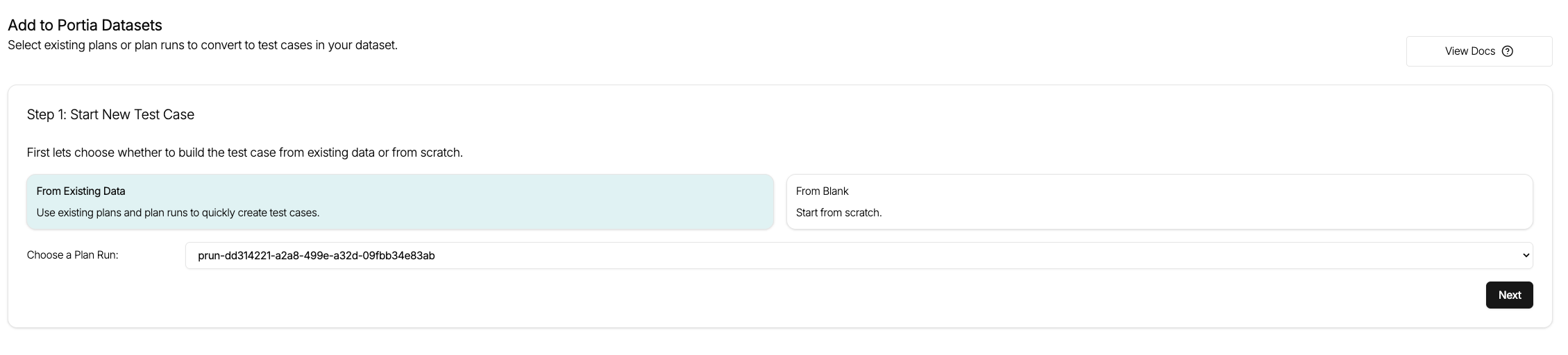
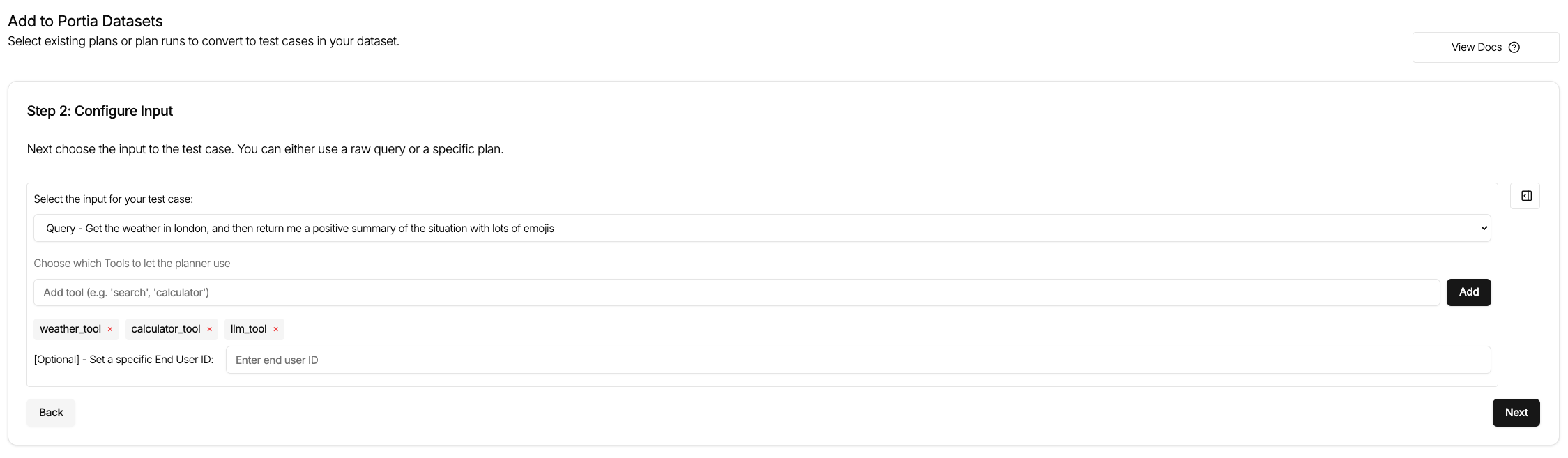
- Step one of the process is about specifying the input to Portia. Either a query or an existing plan can be provided depending on your use case.
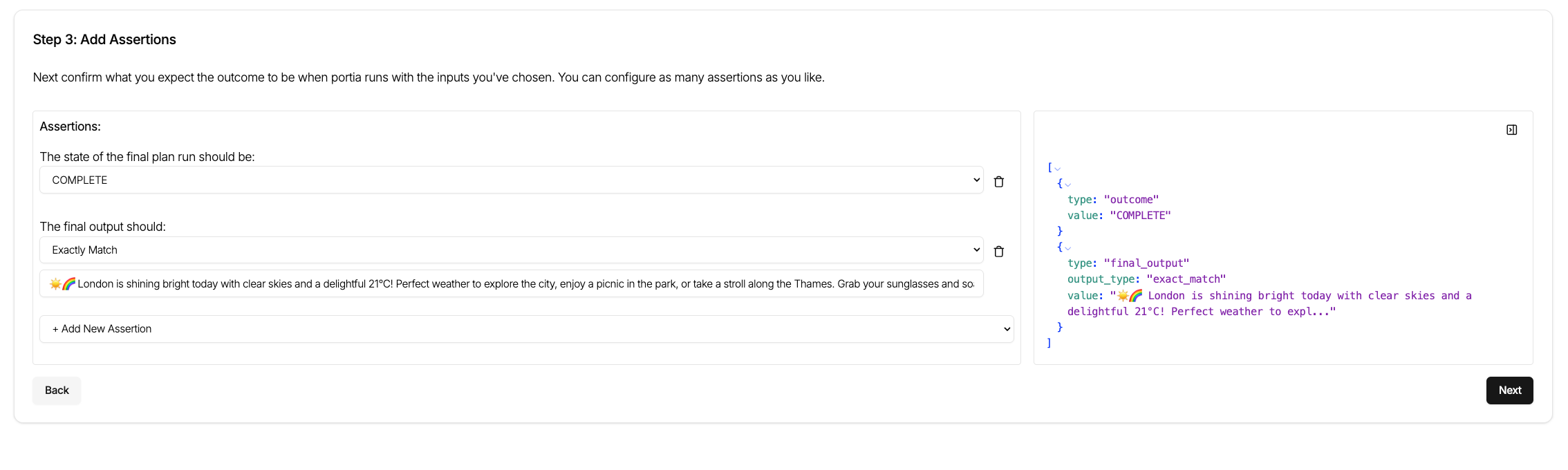
- Step two involves the assertions that we will make when the plan_run is complete. This allows you to use the built in evaluators or to use custom tags.
- Finally give the test case a description to make it easy to understand whats going on it in.

You can add plan runs into an existing Eval dataset directly from the Plan Run view. When you're in the Plan Runs tab in the dashboard, click on the plan run you want to add to your Eval dataset, and look for the 'Add to Evals' button in the Plan Run view modal. This is perfect when you're iterating on an agent in development, so that you can immediately add your ideal plan run to your Evals once you manage to produce it.
With the setup above completed you're now ready to run this basic example.
from portia import Config, Portia
from steelthread.steelthread import SteelThread, EvalConfig
# Initialize Portia
config = Config.from_default()
portia = Portia(config=config)
# Initialize SteelThread with the dataset and evaluators set in the dashboard
st = SteelThread()
st.run_evals(
portia,
EvalConfig(
eval_dataset_name="your-dataset-name-here",
config=config,
iterations=5,
),
)
Default evaluators
Steel Thread comes with a decent helping of evaluators by default. The EvalConfig object above takes a list of evaluators (of type Evaluator) as an argument. SteelThread's DefaultEvaluator is available off the shelf and is used by default when no evaluators are specified. It picks up all the evaluators you set up in the dashboard, of which the available options currently include:
- Final plan run state -- this not only helps you test for a successful plan completion (State =
COMPLETE), but it also helps you test for plans that should fail or trigger a clarification e.g. for auth. - Tool calls -- you can confirm whether all the tools you expected to be called were indeed called (and include an exclusion set as well e.g. to track tool selection confusion).
- Latency -- how long a plan run took to complete.
- LLM judge on plan run -- feed the whole plan run with some guidance to an LLM as judge.