Custom evaluators
Evaluators are responsible for the calculation of metrics. To help you get started quickly, Steel Thread provides a multitude of built-in evaluators you can configure from the dashboard and then pass to your EvalRun via the DefaultEvaluator class. This explained in the previous section on basic usage.
You can add your own custom evaluators, be it LLM-as-Judge or deterministic ones. Evaluator implements a single methods.
from portia import Plan, PlanRun
from steelthread.evals import EvalTestCase, EvalMetric, PlanRunMetadata, Evaluator
class MyEvaluator(Evaluator):
def eval_test_case(
self,
test_case: EvalTestCase,
final_plan: Plan,
final_plan_run: PlanRun,
additional_data: PlanRunMetadata,
) -> list[EvalMetric] | EvalMetric | None:
# Implementation goes here
pass
We have seen how to implement a custom LLM-as-Judge as part of the default evaluators from the dashboard so let's focus on using custom assertions to implement a custom, deterministic evaluator. To do that you can attach an assertion to your test case from the dashboard, then use a custom evaluator to assess whether your Eval run complied with it:
- From the dashboard, navigate to your Eval set and then to the specific test case. Click on the edit icon on the right end of the row.
- Scroll to the bottom and under 'Add Evaluators' select
Run some custom logic based on tags. - Enter
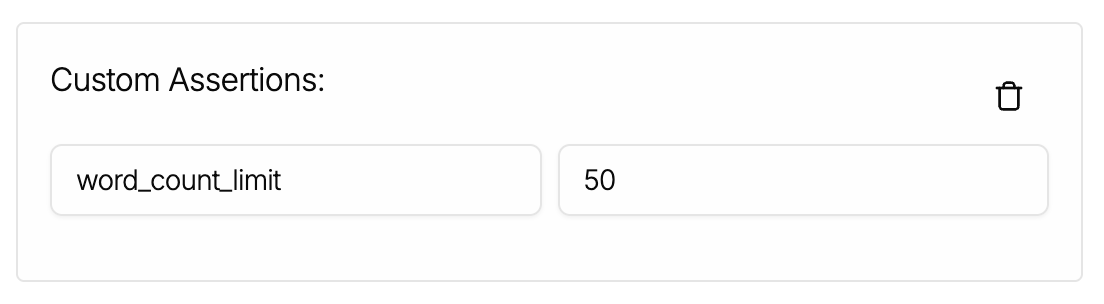
word_count_limitin the Key textbox and50in the Value textbox. This assertion is basically offering this key:value pair as the ground truth reference. - Don't forget to scroll back up and hit that 'Save Changes' button (yeah we need to fix the UX so you don't need to scroll so much!).
 |  |
Next we will write a custom evaluator that detects whenever a test case includes an expected_emojis custom assertion so make sure you set that up for one or more test cases in your desired dataset. The custom evaluator loads the value of the custom assertion using the get_custom_assertion method and compares the plan run outputs to it. In this case we are counting the emojis in the final plan run output final_plan_run.outputs.final_output.get_value(), and comparing it to the expected_emojis number entered in the custom assertion via dashboard.
from portia import Config, Portia, Plan, PlanRun
from steelthread.steelthread import SteelThread, EvalConfig
from steelthread.evals import EvalMetric, Evaluator, EvalTestCase, PlanRunMetadata
import re
# Custom evaluator implementation to count emojis
class EmojiEvaluator(Evaluator):
def eval_test_case(
self,
test_case: EvalTestCase,
final_plan: Plan,
final_plan_run: PlanRun,
additional_data: PlanRunMetadata,
) -> list[EvalMetric] | EvalMetric | None:
# Load plan run output value
string_to_score = (
f"{final_plan_run.outputs.final_output.get_value()}"
if final_plan_run.outputs.final_output
else ""
)
# Count emojis in the loaded output
emoji_pattern = re.compile(
"[\U0001f600-\U0001f64f" # emoticons
"\U0001f300-\U0001f5ff" # symbols & pictographs
"\U0001f680-\U0001f6ff" # transport & map symbols
"\U0001f1e0-\U0001f1ff" # flags
"]+",
flags=re.UNICODE,
)
emojis = emoji_pattern.findall(string_to_score)
emoji_count = len(emojis)
# Compare to the custom assertion
expected = int(test_case.get_custom_assertion("expected_emojis") or 2)
score = min(emoji_count / expected, 1.0)
return EvalMetric.from_test_case(
test_case=test_case,
name="emoji_score",
score=score,
description="Returns a number lower than 1 if the final output is below max emoji count",
explanation=f"Target: {expected}, Found: {emoji_count}",
)
# Initialize Portia
config = Config.from_default()
portia = Portia(config=config)
# Initialize SteelThread with our custom evaluator to run on your dataset
st = SteelThread()
st.run_evals(
portia,
EvalConfig(
eval_dataset_name="your-eval-dataset-name-here",
config=config,
iterations=5,
evaluators=[EmojiEvaluator(config)],
),
)
You should now be able to see emoji_score as a new metric for your dataset in the dashboard.