Using agent memory
With Portia, agents can leverage memory by default. This allows them to work efficiently when large pieces of data are produced / processed during plans, avoiding latency, cost and performance issues caused when language model context windows fill up.
When a step of a plan produces a large output, for example if a large document is read or downloaded, agents in Portia will automatically store this output in agent memory. In their plan run state, they also maintain a reference to this output. Then, if the large output is needed by future steps when running the plan, the value will be pulled in from agent memory as needed.
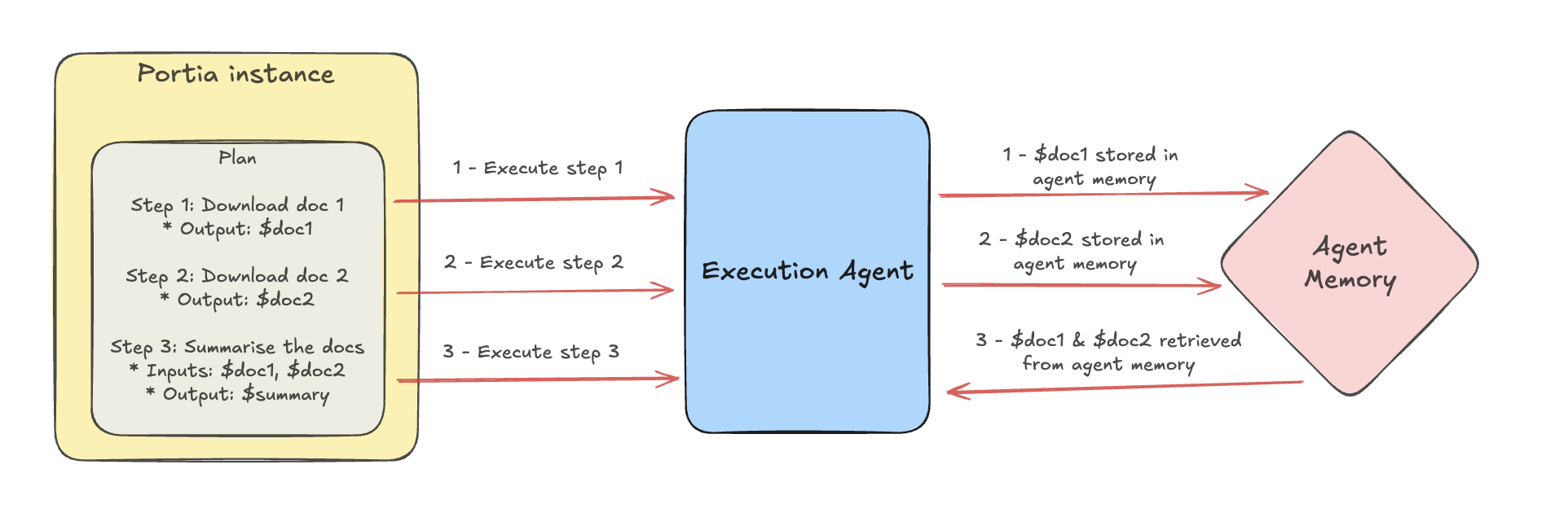
Agent memories are scoped to a particular run of a plan and persist when a plan is paused to handle a clarification and later resumed. If you are running with Portia cloud storage, you can view the values your agents have stored in agent memory by navigating to the Agent Memory page ↗.
Configuring agent memory
Agent memory uses the storage class that you have configured for your Portia client. This means you can store memories locally, in the Portia cloud or on disk. For more details on the available storage classes, see our storage options section ↗.
You can also configure the size threshold at which step outputs are written to agent memory using the large_output_threshold_tokens config value:
portia = Portia(Config.from_default(large_output_threshold_tokens=10000))
Step outputs longer than this threshold are automatically written to agent memory. This threshold is expressed in tokens, which is a unit of text processed by a language model. They can be thought of as being roughly equivalent to words, but with some words taking several tokens. For more details, see this explainer on language model tokens ↗.